
티스토리 뷰
독립변수와 종속변수
데이터 분석과 통계학에서 독립변수와 종속변수는 연구 설계와 모델 구축에서 매우 중요한 개념입니다:
- **독립변수(Independent variable)**는 실험이나 모델에서 조작하거나 통제하는 변수입니다. 이 변수는 다른 변수에 영향을 줄 수 있으며, 일반적으로 원인으로 간주됩니다. 예를 들어, 특정 약의 효과를 검증하는 실험에서 약의 용량은 독립변수일 수 있습니다.
- **종속변수(Dependent variable)**는 독립변수에 의해 영향을 받는 변수로, 실험이나 관찰의 결과로 간주됩니다. 이는 일반적으로 결과나 효과를 나타내며, 연구의 주요 관심사입니다. 예를 들어, 약의 효과를 보는 실험에서 환자의 증상 개선 정도는 종속변수가 됩니다.
Random Forest 분석
Random Forest는 분류(Classification)와 회귀(Regression) 문제에 사용되는 머신러닝 알고리즘입니다. 이 알고리즘은 결정 트리(Decision Tree)의 앙상블로 구성되며, 다음과 같은 특징을 가지고 있습니다:
- 앙상블 학습: Random Forest는 여러 개의 결정 트리를 생성하고, 각 트리의 예측을 결합하여 최종 결과를 도출합니다. 이 과정에서 각 트리는 서로 다른 데이터 샘플과 특성을 사용하여 훈련됩니다(부트스트랩 샘플링).
- 분류 및 회귀: 이 알고리즘은 데이터의 카테고리를 예측하는 분류 문제와 수치적 값을 예측하는 회귀 문제 모두에 사용할 수 있습니다.
- 오버피팅 방지: 개별 결정 트리는 종종 오버피팅(과적합) 경향이 있지만, Random Forest는 여러 트리를 평균 내거나 다수결로 결합함으로써 오버피팅 문제를 효과적으로 완화할 수 있습니다.
- 특성 중요도: Random Forest는 모델의 예측에 각 특성이 얼마나 중요한지 평가할 수 있게 해주며, 이는 특성 선택에 유용하게 사용될 수 있습니다.
예시 사용
예를 들어, 고객 데이터를 바탕으로 고객의 상품 구매 여부를 예측하는 문제에서:
- 독립변수는 고객의 연령, 성별, 구매 이력 등이 될 수 있습니다.
- 종속변수는 고객이 특정 상품을 구매할지 여부(예: 구매/비구매)입니다.
- 이러한 문제에 Random Forest를 적용하면, 각 고객의 정보를 바탕으로 구매할 가능성을 예측할 수 있으며, 어떤 특성이 구매 예측에 중요한 역할을 하는지도 파악할 수 있습니다.
로지스틱 회귀
로지스틱 회귀(Logistic Regression)는 분류 문제를 해결하기 위한 통계적 모델로, 특히 이진 분류(결과가 두 가지인 경우)에 주로 사용됩니다. 이 모델은 독립 변수의 선형 조합을 사용하여 사건의 발생 확률을 추정합니다.
아래는 로지스틱 회귀 모델을 생성하고, Min-Max 정규화를 적용한 후 F1-score로 모델을 평가하는 간단한 Python 예시입니다
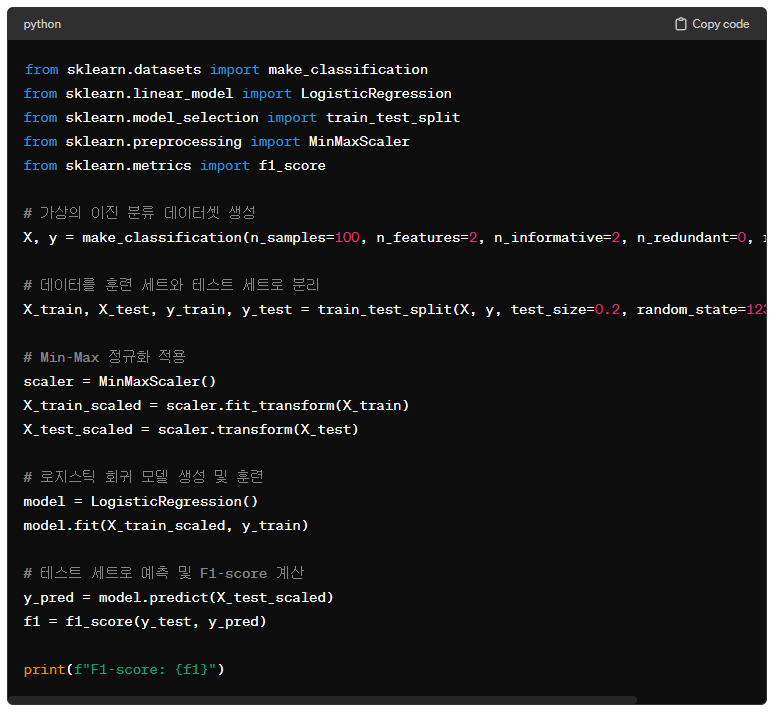
위 예제에서는 sklearn 라이브러리의 여러 기능들을 사용했습니다.
- make_classification 함수로 가상의 분류 데이터셋을 생성합니다.
- train_test_split 함수로 데이터를 훈련 세트와 테스트 세트로 분리합니다.
- MinMaxScaler로 특성 데이터의 스케일을 정규화합니다.
- LogisticRegression 모델을 생성하고 훈련 세트로 학습시킵니다.
- 학습된 모델로 테스트 세트의 데이터에 대한 예측을 수행합니다.
- f1_score 함수로 실제값과 예측값을 비교하여 F1-score를 계산합니다.
이렇게 모델을 훈련하고 평가하는 과정은 분류 문제에 대한 기본적인 접근 방법입니다.
정규화는 모델의 성능을 개선할 수 있는 중요한 단계이며, F1-score는 불균형한 데이터셋에서 모델의 성능을 평가하는 데 유용한 지표입니다.
- make_classification 함수:
- Scikit-learn 라이브러리의 make_classification 함수는 분류용 가상 데이터를 생성하는 데 사용됩니다. 사용자가 지정한 수의 샘플, 특성, 정보 있는 특성의 수, 중복된 특성의 수 등에 기반하여 데이터셋을 만들어냅니다.
- train_test_split 함수:
- train_test_split은 데이터셋을 훈련 세트와 테스트 세트로 나누는 데 사용됩니다. 보통 데이터의 일정 비율을 테스트 세트로 분리하여 모델의 성능을 검증할 때 사용되며, 이 과정에서 데이터의 일반화 능력을 평가할 수 있습니다.
- MinMaxScaler:
- MinMaxScaler는 데이터의 각 특성의 값이 특정 범위(기본적으로 0과 1 사이)에 놓이도록 정규화하는 방법입니다. 이는 모든 특성이 같은 스케일을 갖도록 해서, 특성 간의 불균형이 모델 성능에 미치는 영향을 줄이기 위해 사용됩니다.
- LogisticRegression 모델:
- LogisticRegression은 로지스틱 회귀 분석을 수행하는 머신러닝 모델입니다. 주로 이진 분류 문제를 해결할 때 사용되며, 각 샘플이 특정 클래스에 속할 확률을 추정하여 분류 결정을 내립니다.
- 모델의 예측 수행:
- 학습된 LogisticRegression 모델을 사용하여, 테스트 세트에 대한 예측을 수행합니다. 이는 모델이 새로운 데이터에 대해 얼마나 잘 일반화하는지를 보여줍니다.
- f1_score 함수:
- f1_score 함수는 실제 타겟 레이블과 모델의 예측 레이블을 비교하여 F1 점수를 계산합니다. 이 점수는 정밀도와 재현율의 조화 평균을 나타내며, 모델이 데이터의 양성 클래스를 얼마나 잘 예측하는지에 대한 정보를 제공합니다. F1 점수는 0에서 1 사이의 값을 가지며, 값이 높을수록 모델의 성능이 좋다고 할 수 있습니다.
이러한 과정을 통해 데이터를 준비하고, 모델을 학습시키며, 모델의 성능을 평가하는 데 필요한 주요 단계와 용어들에 대한 이해를 돕습니다.
문제
~~~ 종속변수로 하는 모델을 만들어보고자 한다.
데이터 분할 후 정규화를 실시하여 로지스틱 회귀분석을 실시하고 해당 모델을 기준점 삼아 모델을 개선하고자 한다.
주어진 독립변수를 활용하여 F1-score로 모델을 평가하시오.
1. 데이터 분할
df_train, df_test = train_test_split(df_q3, train_size = 0.7, random_state = 123)
이 줄은 train_test_split 함수를 사용하여 데이터프레임 df_q3을 훈련 세트(df_train)와 테스트 세트(df_test)로 분할합니다. train_size = 0.7은 전체 데이터의 70%를 훈련용으로, 나머지 30%를 테스트용으로 사용하겠다는 것을 의미하며, random_state = 123은 이 분할이 일관되게 재현가능하도록 합니다.
2. 정규화 모델 피팅
model_nor = MinMaxScaler().fit(df_train)
MinMaxScaler를 생성하고, 훈련 데이터에 맞춰(fit) 정규화 모델을 훈련합니다. 이는 훈련 데이터의 각 특성의 최소값과 최대값을 계산하여 저장합니다.
3. 데이터 정규화
arr_train_nor = model_nor.transform(df_train)
arr_test_nor = model_nor.transform(df_test)
훈련 데이터와 테스트 데이터를 정규화하여 특성들이 0과 1 사이의 범위를 갖도록 변환합니다.
4. 로지스틱 회귀 모델 생성
model_lr = LogisticRegression(random_state = 123)
LogisticRegression 모델 객체를 생성합니다. random_state는 결과의 재현성을 위해 설정합니다.
5. 모델 훈련
model_lr.fit(X = arr_train_nor[:, 1:], y = arr_train_nor[:, 0])
fit 메소드를 사용하여 로지스틱 회귀 모델을 훈련합니다. 여기서 arr_train_nor[:, 1:]는 첫 번째 열을 제외한 모든 열(독립 변수)을, arr_train_nor[:, 0]는 첫 번째 열(종속 변수, 레이블)을 나타냅니다.
x : 이렇게 한 이유는, df_q3의 첫번째 열이 "종속변수"이므로, 해당 열을 제외하는 것.
y : 첫번째 열이 종속변수므로 첫번째 열만 가져오기
6. 모델 예측
pred = model_lr.predict(arr_test_nor[:, 1:])
학습된 모델을 사용하여 테스트 데이터셋에 대한 예측을 수행합니다.
예측 수행 시에도 첫 번째 열을 제외하고 시행한다.
7. F1-score 계산
round(f1_score(y_true = arr_test_nor[:, 0], y_pred = pred), 2)
f1_score 함수는 모델의 예측 성능을 평가하기 위해 사용되며, y_true는 실제 레이블값, y_pred는 모델의 예측값을 인자로 받습니다. arr_test_nor[:, 0]는 테스트 데이터의 실제 레이블을 나타내며, pred는 모델의 예측값입니다. round( , 2) 함수는 계산된 F1-score를 소수점 둘째 자리까지 반올림합니다.
회귀 분석 강의 참고
'Python 데이터사이언스' 카테고리의 다른 글
| Scikit-learn 주요 라이브러리 정리 (GPT4) (0) | 2024.04.19 |
|---|---|
| Pandas 주요 라이브러리 정리 (GPT4) (0) | 2024.04.19 |
| Pandas, Numpy, Scikit-learn, SciPy 설명/예시/메인함수 정리 (GPT4) (0) | 2024.04.19 |
| UnicodeDecodeError: 'cp949' codec can't decode byte 0xed in position 0: illegal multibyte sequence 해결방법 (0) | 2023.09.09 |
| AttributeError: 'str' object has no attribute 'capabilities' 해결방법 (0) | 2023.09.09 |
- Total
- Today
- Yesterday
- 해결방법
- 엔진오일
- 겨울
- 겨울러그
- 캠핑
- 쿠팡
- 수원
- 디아블로4
- 코인
- 데이터사이언스
- 에러
- 컴인워시
- 다이나믹 프로그래밍
- 레스토랑
- 오미크론
- problem
- 맛집
- Algorithm
- Algorithm Schedule
- 오픽
- 원소술사
- NFT
- 3만원대
- 호텔
- 가성비
- 여름
- 24년
- python
- 삼성전자
- 단열벽지
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |