728x90
1. Pandas:
Pandas는 주로 데이터 조작과 분석에 사용됩니다. 특히, 테이블 데이터를 처리하고, CSV/Excel 파일을 읽고 쓰며, 데이터를 정리하고, 분석하기 위해 사용됩니다.
예시:
- 금융 데이터 분석에서 주식의 시간별 가격 변동성을 계산할 때
- 데이터 과학에서 결측치 처리, 데이터 타입 변환, 데이터 통합 및 변환 작업을 할 때
2. NumPy:
NumPy는 수치 계산에 사용되며, 대규모 다차원 배열과 행렬 연산에 최적화되어 있습니다. 또한, 고수준 수학 함수를 제공하여 수학적 연산을 수행합니다.
예시:
- 컴퓨터 과학에서 이미지나 오디오 데이터를 배열로 변환하여 처리할 때
- 엔지니어링 계산에서 행렬 연산, 푸리에 변환, 또는 랜덤 시뮬레이션 등을 수행할 때
3. Scikit-learn (sklearn):
Scikit-learn은 머신 러닝 모델을 구축하고 평가하기 위해 사용됩니다. 분류, 회귀, 클러스터링 알고리즘과 함께 교차 검증, 파라미터 튜닝 등을 위한 다양한 도구를 제공합니다.
예시:
- 이메일에서 스팸을 식별하는 분류기를 만들 때
- 고객 데이터를 기반으로 구매 가능성을 예측하는 회귀 분석을 할 때
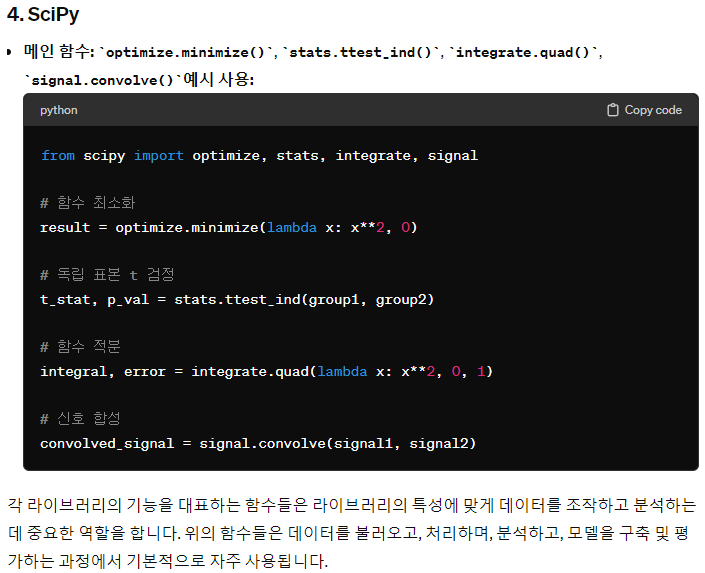
4. SciPy:
SciPy는 과학적 계산을 위한 라이브러리로, 최적화, 통계, 신호 처리 등의 작업을 위해 사용됩니다. Pandas, NumPy, Matplotlib와 함께 사용되어 과학 및 엔지니어링 애플리케이션에 널리 적용됩니다.
예시:
- 물리학에서 실험 데이터를 분석하여 모델 파라미터를 최적화할 때
- 생물통계학에서 의학 데이터를 분석하여 통계적 유의성을 평가할 때



728x90
반응형
'Python 데이터사이언스' 카테고리의 다른 글
| Pandas 주요 라이브러리 정리 (GPT4) (0) | 2024.04.19 |
|---|---|
| 독립변수와 종속변수, Radom Forest 분석 간단 정리 (GPT4) (0) | 2024.04.19 |
| UnicodeDecodeError: 'cp949' codec can't decode byte 0xed in position 0: illegal multibyte sequence 해결방법 (0) | 2023.09.09 |
| AttributeError: 'str' object has no attribute 'capabilities' 해결방법 (0) | 2023.09.09 |
| 파이썬 웹 컴파일러 ideone (2) | 2023.07.15 |